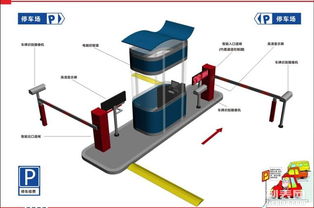
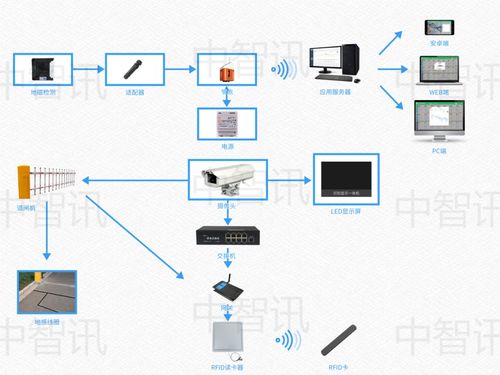
廈門海滄宏運 以專業研發鑄就高品質、可信賴的智能卷閘門與護欄門禁安防系統

在現代化城市建設與安防需求日益提升的背景下,廈門海滄區的宏運公司憑借其深厚的技術積淀與專注的研發精神,在卷閘門、智能護欄及門禁安防系統領域樹立了“高品質、可信賴”的專業形象。公司不僅提供堅固耐用的物理防護產品,更致力于通過前沿技術的融合創新,打造智能化、集成化的整體安防解決方案。
一、 核心產品線:品質為基,專業鑄就
- 高品質卷閘門:宏運的卷閘門產品采用優質鍍鋅鋼板、鋁合金或高強度復合材料,結構設計科學,具有抗風壓、耐腐蝕、運行平穩靜音等特點。嚴格的生產工藝與質量控制體系,確保了每一扇門都具備長壽命和高可靠性,廣泛適用于商鋪、倉庫、廠房及各類民用設施。
- 智能護欄系統:超越傳統的簡單圍擋,宏運的智能護欄集成了傳感器、驅動與控制單元。它不僅能實現自動升降、平移,還可具備防撞、防爬越報警功能,并能根據預設時間或指令自動運行,極大地提升了區域管控的便捷性與安全性,適用于小區、園區、停車場等周界防護。
- 集成化門禁安防系統:這是宏運技術研發的核心體現。系統以門禁控制為中樞,深度融合視頻監控、入侵報警、消防聯動、身份識別(如IC卡、指紋、人臉、車牌識別)等多種技術。通過統一的軟件管理平臺,用戶可以實現遠程監控、權限管理、事件記錄與回溯、多設備聯動響應,構建起立體化、智能化的安全屏障。
二、 技術研發驅動:智能與專業的深度融合
宏運公司的核心競爭力源于其持續的技術研發投入:
- 物聯網(IoT)集成:將卷閘門、護欄等終端設備接入物聯網,實現狀態實時監控、故障預警和遠程運維,變被動維修為主動維護。
- 人工智能(AI)應用:在視頻分析中引入AI算法,實現異常行為識別、人數統計、危險物品檢測等功能,提升安防系統的預警能力和智能化水平。
- 驅動與控制技術優化:研發高效、低噪音的電機驅動系統和精準穩定的控制邏輯,確保門體運行既快速又平穩,同時降低能耗。
- 結構力學與材料科學:針對廈門沿海地區多風、潮濕的氣候特點,專項研究產品的抗風壓結構設計和表面處理工藝,確保其在惡劣環境下性能依舊穩定。
- 網絡安全與數據加密:對于聯網的智能系統,高度重視數據傳輸與存儲的安全,采用加密協議和防火墻技術,防止系統被非法入侵或篡改,保障用戶隱私與系統穩定。
三、 可信賴的服務體系
“可信賴”不僅體現在產品品質上,更貫穿于整個服務鏈條。宏運公司提供從前期咨詢、方案定制、專業安裝到售后維護、技術升級的一站式服務。擁有經驗豐富的技術團隊,能夠快速響應客戶需求,解決各類技術問題,確保每一個安防系統都能長期穩定運行,為客戶創造持久價值。
廈門海滄宏運公司正以“專業”為舵,以“技術研發”為帆,在智能安防的藍海中穩步前行。通過對卷閘門、智能護欄及門禁安防系統的不懈深耕與創新,宏運不僅為海滄乃至廈門地區的客戶提供了堅固的實體防護,更通過智能化手段賦予了安防系統以“智慧”,用實際行動詮釋著“高品質、可信賴”的承諾,守護著千家萬戶與各行各業的安全與安寧。
如若轉載,請注明出處:http://www.fecpub.cn/product/79.html
更新時間:2026-06-19 15:33:11